Ever wondered how huge companies like Netflix and Instagram keep their apps running smoothly with millions of users online at once? One of the secret weapons behind their data systems is Apache Cassandra, a fast, reliable, and highly scalable database. Cassandra is the database of choice for companies that need to handle tons of data with zero downtime, and it does that with a unique architecture that’s both powerful and elegant.
But what makes Cassandra so resilient and scalable under the hood? If you’ve just started exploring distributed systems or databases, Apache Cassandra might seem like a complex beast. But let’s peel this complex robust architecture of this mammoth database layer by layer!
If you are completely new to Cassandra, you may find the previous write-up helpful. Feel free to pause here and read “Cassandra: Write Fast, Scale Forever“.
What is Cassandra
Cassandra is a distributed decentralized column-oriented open-source NoSQL database with high availability which is highly scalable with tunable consistency.
This definition includes some key concepts from distributed systems. If you’re familiar with that area, these terms might already make sense.
But don’t worry if you’re new to distributed systems or even to computer science in general. We’ll break down everything step by step, so it’s easy to follow.
Let’s get started by understanding the building blocks of Cassandra’s architecture.
Distributed Database
A distributed system is one where data and computation are not confined to a single server or machine but spread across multiple nodes.
In the case of Cassandra, the data is distributed among a collection of nodes which are the servers or machines, called as a cluster. In the cluster, there are no master or slave nodes! The clusters are homogeneous which means they are all equally capable of performing reads and writes.
These clusters combined with replications makes the database highly available and eliminates the problem of single point of failure: SPoF. A Cassandra cluster can be connected to one or more clusters which may be located in different physical locations or datacenters facilitating availability of data even if one or more cluster or datacenter go down.
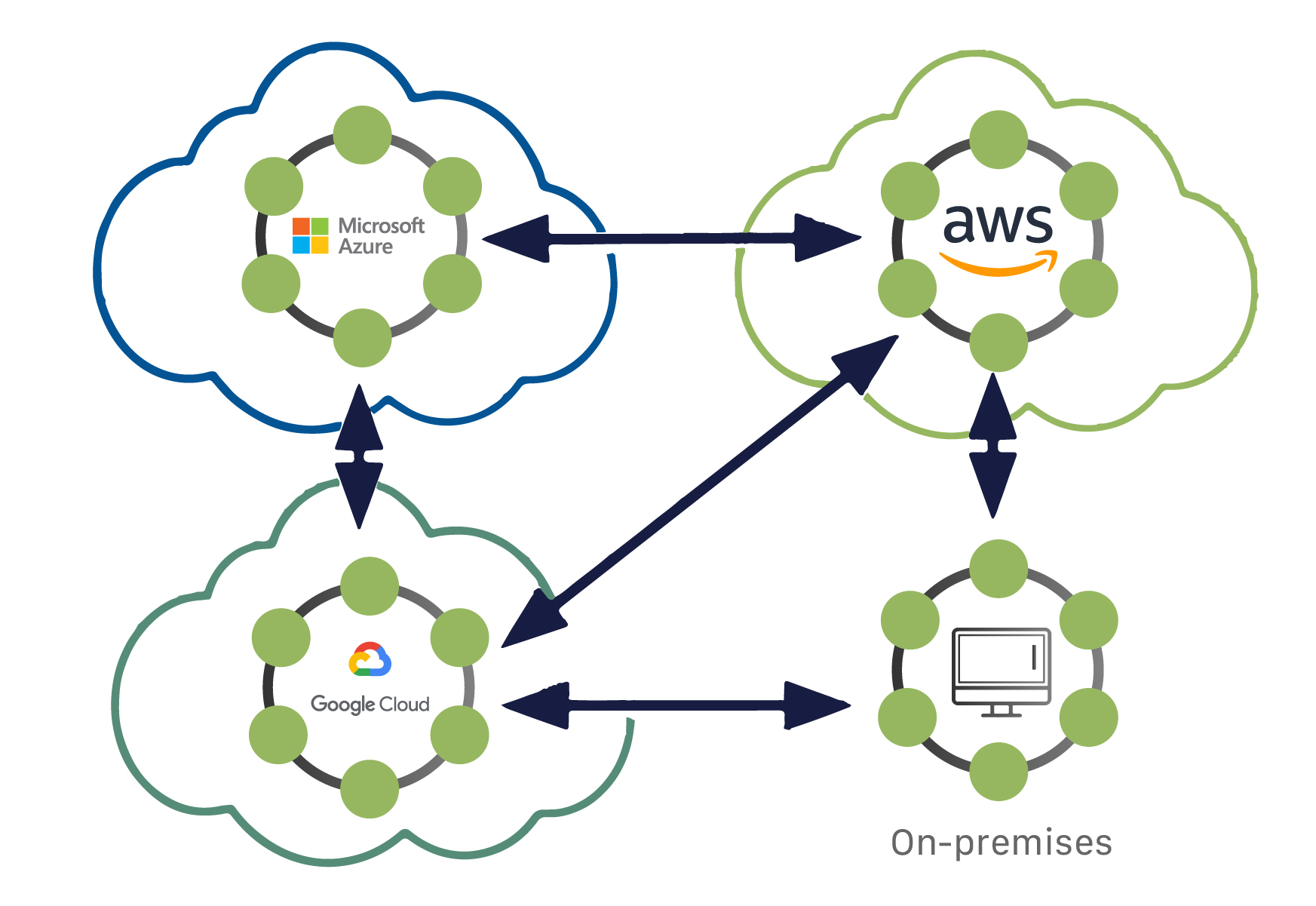
Cassandra can hold Petabytes of data and each node can handle as much data limited by it’s physical or virtual capabilities.
A few companies who are using Cassandra and storing and processing enormous amount of data:
- Apple reportedly runs over 75,000 Cassandra nodes, and stores more than 10 PB of data. At least one cluster has over 1,000 nodes and handles millions of operations per second.
- Netflix operates more than 10,000 Cassandra instances, storing around 6 PB of data across 100+ clusters. The deployment handles over 1 trillion requests per day.
- Uber operate hundreds of Cassandra clusters, many with 400+ nodes each.
For a node, the recommended data size should be under 2 to 4 TB per node (on SSDs) for optimal performance. Some use cases push up to 10 or 20 TB per node, but GC pauses and compaction overhead grow with size. But the custer size can be infinite!
Distribution of Data
Now we know the meaning of a distributed database, it’s time to understand how the data is organized among the connected nodes in a cluster.
Cassandra uses consistent hashing for distribution of data across the nodes in a cluster using a partitioner.
Consistent hashing strive for even distribution of data across nodes of a cluster. This allows the database to evenly distribute the load of a table data onto the different nodes in the cluster. Unlike relation databases, it is not required in Cassandra to store all the rows of a table in a particular node of a cluster. One of the key benefits of partitioning the data is that it allows the cluster to grow incrementally.
Logical Representation
Cassandra cluster is denoted as a ring structure, where each node is assigned a range of tokens. When a partition key is written, it is hashed into a token value, and this token is mapped to a position on the ring. This ring-based architecture allows Cassandra to achieve decentralized, scalable, and fault-tolerant data distribution, making it easy to add or remove nodes with minimal rebalancing.
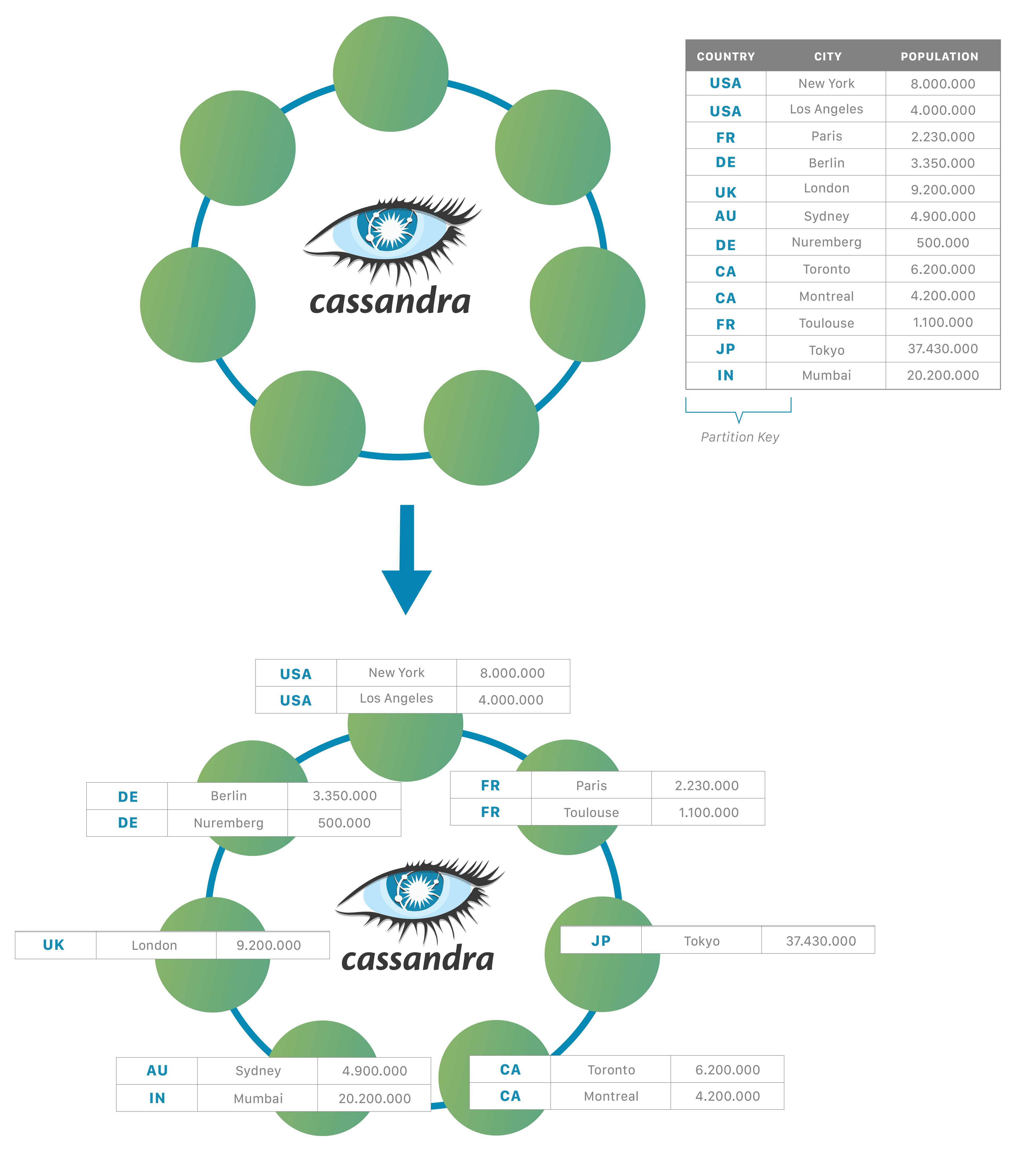
Partitioner
Cassandra use a partitioner, which determines (with the help of an algorithm) that on which node a particular row of a table will be stored. The default partitioner in Cassandra (v1.2+) is the Murmur3. This is a hashing algorithm which generates a 64-bit signed token.
A few other available partitioners are:
- RandomPartitioner: It used the MD5 hashing, which generates 128-bit tokens for data distribution. Cassandra 1.1x and before have this as the default.
- ByteOrderPartitioner: it sorts keys lexicographically (alphabetically). Since this is an ordered distribution, this partitioner is avoided as it can easily cause a hotspot.
Node Communication
In distributed systems like Cassandra, traditional client-server communication models (like HTTP or RPC) are not practical. Especially when dealing with hundreds or thousands of nodes. Instead, Cassandra uses a fully decentralized, peer-to-peer architecture.
Since all the nodes are equally powerful and there is no master node, how do nodes discover and communicate with each other?
The important components in the Cassandra communication system are: The Snitch and The Gossip Protocol.
Snitch
A snitch is a crucial component responsible for providing the database with information about the network topology—specifically, the data center and rack placement of each node in the cluster. It is a protocol that helps map IPs to racks and data centers.
This topology awareness is essential for replication strategies (we will learn about them later), as it helps Cassandra intelligently place replicas across different physical or logical locations to ensure high availability and fault tolerance.
The several types of snitch are:
| Name | Definition |
|---|---|
| Dynamic Snitching | Monitors real-time read latency and dynamically adjusts replica selection. Helps avoid slow or overloaded nodes during query routing. |
| SimpleSnitch | Assumes all nodes are in the same data center and rack. Best for local development or simple single-node clusters. |
| PropertyFileSnitch | Uses a static cassandra-topology.properties file for rack and DC info. Requires manual updates when topology changes. |
| GossipingPropertyFileSnitch | Reads topology from cassandra-rackdc.properties and shares it via Gossip. Supports dynamic cluster updates and is the default for production. |
| Ec2Snitch | Automatically maps AWS availability zones as racks in a single region. Good for single-region AWS deployments. |
| Ec2MultiRegionSnitch | Treats AWS regions as data centers and availability zones as racks. Ideal for multi-region AWS-based deployments. |
On first install Cassandra uses the SimpleSnitch by default. This snitch assumes that all nodes are in the same data center and rack, which works fine for basic setups or development environments.
However, in real-world deployments, Cassandra is often used across multiple data centers or cloud regions. In such cases, more advanced snitches are needed to account for the network topology. That’s where other snitch types come in, such as the GossipingPropertyFileSnitch, which understands and communicates the data center and rack information across the cluster.
1 | # Datacenter One |
Sample cassandra-topology.properties file which is setting up two physical datacenters with 2 racks each.
1 | -- Keyspace creation for a PropertyFileSnitch based setup |
Seed Node
Some nodes in a Cassandra cluster are designated as seed nodes for the others. They are configured to be the first nodes to start in the cluster. They also facilitate the bootstrapping process for the new nodes joining the cluster. When a new node comes online, it will talk to the seed node to obtain information about the other nodes in the
cluster.
Gossip
The gossip protocol is what the nodes in a cluster uses for communication with each other.
Every second, each node communicates with up to 3 other nodes. The node exchanges information about itself and all the information of the other nodes it knows about. Gossip is the internal method of communication for nodes in a cluster to talk to each other.
TThe gossip protocol helps nodes:
- Discover new nodes joining the cluster.
- Detect node failures quickly.
- Share metadata like data ownership, load, and schema versions.
- Maintain an up-to-date and consistent view of the cluster without any central coordinator.
Because Gossip is peer-to-peer, it scales efficiently even in large clusters with hundreds or thousands of nodes. It also ensures the cluster is fault-tolerant, as nodes independently monitor each other’s health and status.
The Gossip protocol in Cassandra is a subject in itself and it deserves a separate writing, for now read this article.
Data Replication
One of the key reasons Cassandra remains reliable even during network partitions is its robust data replication mechanism.
To prevent data loss or unavailability in case of node failures or data center outages, Cassandra replicates data across multiple nodes. While replication introduces some storage and network overhead, it is essential for ensuring the database remains fault tolerant.
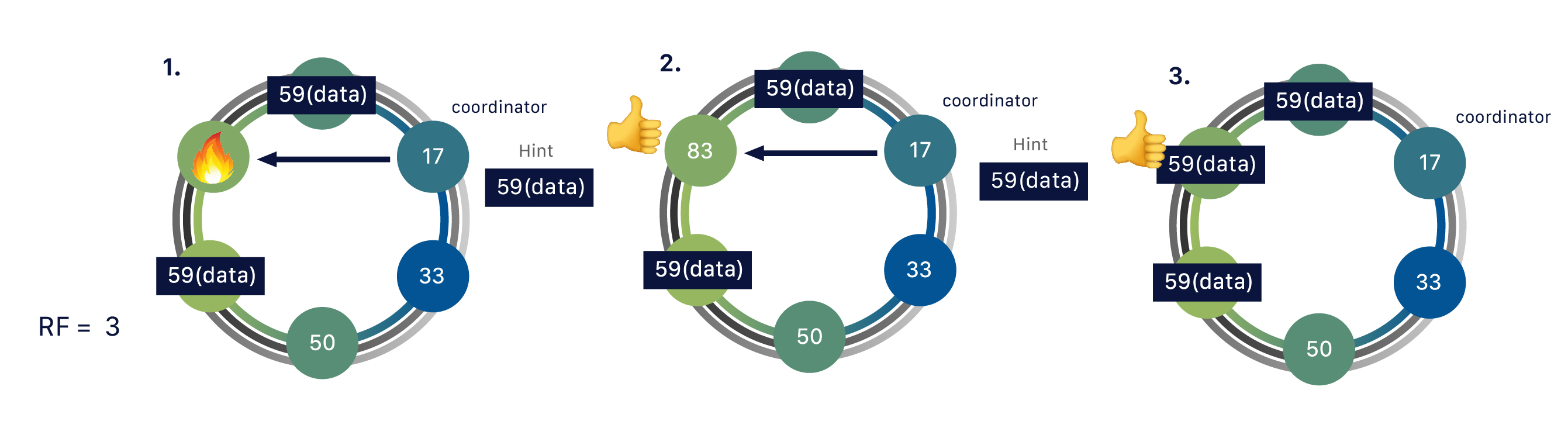
Cassandra provides multiple ways of data replication which we can use while creating a keyspace (aka database in terms of a relational DB). The replication factor (RF) specifies how many copy of the data should be created within a given database.
If the replication factor for a database is 3, (or RF=3), then a row will be written to 3 nodes in the cluster. Now if any of the nodes goes down, no problem. We can retrieve it from any of the other 2 nodes in the cluster.
Cassandra offers different replication strategies to control how replicas are distributed:
- SimpleStrategy: Places replicas on the next RF - 1 nodes clockwise in the ring. Best for single data center deployments.
- NetworkTopologyStrategy: Allows specifying replication factors per data center, distributing replicas across racks for better fault tolerance. Ideal for multi-data center setups.
1 | -- For single data center using SimpleStrategy |
Tunable Consistency
Cassandra provides tunable consistency, allowing us to balance between consistency, availability, and latency based on your application’s needs. Instead of enforcing strict consistency for every operation, We can choose the consistency level per query, either for the reads or the writes.
CAP theorem is critical to know in order to better understand Cassandra’s tunable consistency. CAP is a subject in itself and it deserves a separate writing, for now read this article.
The consistency level (CL) specifies how many replica nodes must acknowledge a read or write operation before it is considered successful.
- Higher consistency levels increase data accuracy but can increase latency or reduce availability if nodes are down.
- Lower consistency levels improve availability and performance but may return stale or partially updated data.
CL for Reads
When a client tries to read data in Cassandra, the consistency level (CL) determines how many replica nodes must respond to the read request before the data is returned to the client. This controls the accuracy of the data the client will receive and how much up to date it is.
| Consistency Level | Description | Example (RF = 3) |
|---|---|---|
ONE |
Returns the response from the first replica to reply. Fastest, but may return stale data. | Reads from 1 replica |
TWO / THREE |
Waits for responses from 2/3 replicas. | Reads from 2/3 replicas |
QUORUM |
Waits for a majority of replicas (⌈(RF/2)+1⌉). Safer and consistent. | Reads from 2 of 3 replicas |
ALL |
Requires all replicas to respond with the same data. Strongest consistency, lowest availability. | Reads from all 3 |
LOCAL_QUORUM |
Waits for a quorum in the local data center. Ideal for multi-DC setups. | Reads from 2 replicas in local DC |
EACH_QUORUM |
Waits for a quorum from each data center. Very strong and network-heavy. | Reads from 2 in each DC |
CQL example of read with CL
1 | -- Reading data with ONE consistency |
CL for Writes
When writing data to Cassandra, the consistency level (CL) determines how many replicas must acknowledge the write before it is considered successful. This setting gives you fine control over the trade-off between availability, consistency, and latency.
Even if all replicas don’t acknowledge, Cassandra will eventually update them using background processes like hinted handoff or repairs.
| Consistency Level | Description | Example (RF = 3) |
|---|---|---|
ANY |
A write is accepted as long as one node (even a hinted one) stores it. | Acknowledged even if no actual replica is available. |
ONE |
At least one replica must confirm the write. | Fast but less consistent. |
TWO / THREE |
Requires acknowledgment from 2 or 3 replicas respectively. | Higher consistency. |
QUORUM |
A majority of replicas must acknowledge (⌈(RF/2)+1⌉). | 2 of 3 replicas must respond. |
ALL |
All replicas must respond. | Strongest, but most fragile. |
LOCAL_QUORUM |
Quorum from the local data center. | Efficient for multi-DC. |
EACH_QUORUM |
Quorum from each data center must respond. | Very strong, cross-DC level. |
CQL example of write with CL
1 | -- Insert with write consistency level QUORUM |
Cassandra Repair Mechanisms
Cassandra is designed for high availability and fault tolerance, which means it allows reads and writes to succeed even if some nodes are temporarily down or unreachable. But this flexibility can lead to data getting out of sync across replicas. Repair mechanisms exist in Cassandra to fix these inconsistencies and ensure that all replicas eventually hold the same data. .
Cassandra has three built in repair mechanisms which help to detect and correct stale or missing updates caused by network issues, node failures, or delayed writes. They are:
- Read Repair
- Hinted Handoff
- Anti-Entropy Node Repair
Read Repair
When a read happens, the coordinator node, the node handling the client request, contacts multiple replicas based on the set consistency level. The fastest replicas reply first, and their responses are checked in memory for mismatches.
In the background, Cassandra also checks the remaining replicas. If it finds any out-of-sync, it sends updates to fix them. This is called read repair.
There’s no dedicated coordinator, so no single point of failure.
Hinted Handoff
Hinted handoff helps bring a failed node back up to date quickly when it rejoins the cluster. If a replica is down during a write, a healthy node stores a hint. This includes the failed node’s info, the affected row key, and the data being written. If all replicas are down, the coordinator holds the hint.
When the failed node comes back, the hint is sent to it so the missed write can be applied. Until then, the write may not show up in reads, which can cause temporary inconsistency.
Anti-Entropy Node Repair
Anti-entropy repair is a manual or scheduled process that compares full datasets between replicas and fixes any differences.
It uses Merkle trees, a hash-based structure to compare data efficiently without transferring everything. This repair is useful for fixing inconsistencies caused by things like missed hints, failed read repairs, or long-term node failures.
This is the most thorough repair mechanism but can be resource-intensive, so it’s usually run during maintenance windows.
Wrap Up
This was quite a dense write up with a lot of concepts to absorb. Whether you are writing application code or managing a Cassandra cluster, these internal mechanisms are essential to understand and apply in your daily work.
There’s still a lot more to explore, but for now, let’s pause here and reflect on what we’ve covered. Taking the time to soak up these fundamentals will make future deep dives into Cassandra much easier to follow.
Stay healthy, stay blessed!